SharePoint list access using the Repository pattern
See also: SharePoint list definition using the Template pattern.
Maybe it’s that the SharePoint API is hard to use. Maybe it’s that coding against SharePoint is about making smaller additions here and there. Maybe it’s that the Patterns & Practices SharePoint Guidance isn’t widely known. Whatever the reason, developing for SharePoint requires equal attention to the separation of presentation, business, and data access code. Hence, starting with data access, we may want to create a repository and route queries through it (the SharePoint Guidance outlines a more sophisticated implementation than the one below):
[TestClass]
public class EmployeesRepositoryTest {
private SPSite _siteCollection;
private SPWeb _site;
private EmployeesRepository _repository;
private readonly Employee _duffyDuck = new Employee {
Id = 1000, Name = "Duffy Duck", HireDate = new DateTime(2009, 12, 1),
Remarks = "Looks like a duck, quacks like a duck, probably is a duck"
};
private readonly Employee _porkyPig = new Employee {
Id = 1001, Name = "Porky Pig", HireDate = new DateTime(2010, 2, 1)
};
private readonly Employee _sylvesterTheCat = new Employee {
Id = 1002, Name = "Sylvester the Cat", HireDate = new DateTime(2010, 3, 1)
};
private readonly Employee _bugsBunny = new Employee {
Id = 1100, Name = "Bugs Bunny", HireDate = new DateTime(2010, 1, 1)
};
public void AddEmployees() {
_repository.AddEmployee(_site, _duffyDuck);
_repository.AddEmployee(_site, _porkyPig);
_repository.AddEmployee(_site, _sylvesterTheCat);
}
public void ClearEmployees() {
var definition = new EmployeesDefinition();
var employees = _site.Lists[definition.ListName];
while (employees.Items.Count > 0)
employees.Items.Delete(0);
}
[TestInitialize]
public void Initialize() {
_siteCollection = new SPSite("http://localhost");
_site = _siteCollection.OpenWeb("/");
_repository = new EmployeesRepository();
ClearEmployees();
AddEmployees();
}
[TestCleanup]
public void Cleanup() {
_site.Dispose();
_siteCollection.Dispose();
}
[TestMethod]
public void AddEmployee_should_add_valid_employee() {
_repository.AddEmployee(_site, _bugsBunny);
var e = _repository.GetEmployeeById(_site, _bugsBunny.Id);
Assert.AreEqual(_bugsBunny.Id, e.Id);
Assert.AreEqual(_bugsBunny.Name, e.Name);
Assert.AreEqual(_bugsBunny.HireDate, e.HireDate);
Assert.AreEqual(_bugsBunny.Remarks, e.Remarks);
}
[TestMethod]
public void GetEmployeesHiredBetween_should_return_2010_hires() {
var from = new DateTime(2010, 1, 1);
var to = new DateTime(2010, 12, 31);
var employees = _repository.GetEmployeesHiredBetween(_site, from, to);
Assert.AreEqual(2, employees.Count);
Assert.AreEqual(_porkyPig.Id, employees[0].Id);
Assert.AreEqual(_sylvesterTheCat.Id, employees[1].Id);
}
}
In the words of Martin Fowler, here’s the essence of the Repository pattern:
A Repository mediates between the domain and data mapping layers, acting like an in-memory domain object collection. Client objects construct query specifications declaratively and submit them to Repository for satisfaction. Objects can be added to and removed from the Repository, as they can from a simple collection of objects, and the mapping code encapsulated by the Repository will carry out the appropriate operations behind the scenes. Conceptually, a Repository encapsulates the set of objects persisted in a data store and the operations performed over them, providing a more object-oriented view of the persistence layer.
In SharePoint terms, business logic should query a repository which in turn queries a SharePoint list. Within the repository, the weakly typed items returned are then mapped to strongly typed data transfer objects, which are returned to the business layer.
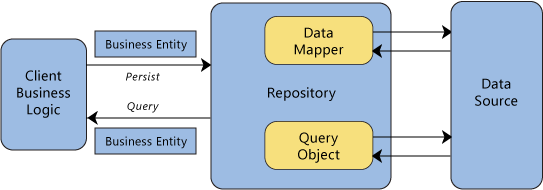
With this approach to data access comes a number of advantages: (1) duplicate data access code is eliminated. Only within the repository do we setup the query and transform the weakly typed SPListItemCollection into strongly typed data transfer objects. (2) The list definition classes introduced in SharePoint list definition using the Template pattern may be used to construct CAML queries from strongly typed field names. Lastly, (3) accessing data through a repository makes it easier to mock the data access part of the application and to integration test that part.
The code below is a simple, yet usable, implementation of the Repository pattern. The idea is to have all repositories inherit from a common base class. Its purpose is to wrap the querying of a list and to log what’s going on. Because it’s a base class, it shouldn’t know how to transform the weakly typed result into strongly data transfer objects or which CRUD operations a particular repository supports:
public abstract class ListRepository {
protected ListDefinition Definition { get; set; }
protected SPListItemCollection Result { get; set; }
protected void Query(SPWeb site, string caml) {
AssertValidSite(site);
AssertValidCaml(caml);
AssertListExistence(site);
AssertListDefinitionSetBySubclass();
var watch = new Stopwatch();
var list = site.Lists[Definition.ListName];
var query = new SPQuery {Query = caml};
Debug.WriteLine(
string.Format("About to run query against list '{0}': {1}", list, caml));
watch.Start();
Result = list.GetItems(query);
watch.Stop();
Debug.WriteLine(
string.Format("Query against '{0}' returned {1} rows in {2} ms",
list, Result.Count, watch.ElapsedMilliseconds));
}
protected void AssertListExistence(SPWeb site) {
if (!ListDefinition.ListExists(site, Definition.ListName))
throw new ArgumentException(
string.Format("No '{0}' list on site '{1}'", Definition.ListName, site.Url));
}
protected void AssertListDefinitionSetBySubclass() {
if (Definition == null)
throw new NullReferenceException(
string.Format(
"Subclass must set Definition property prior querying '{0}' list",
Definition.ListName));
}
protected void AssertValidCaml(string query) {
if (string.IsNullOrEmpty(query))
throw new NullReferenceException("Query must not be null or empty");
}
protected void AssertValidSite(SPWeb site) {
if (site == null)
throw new NullReferenceException("Site must not be null");
}
}
Each ListRepository connects to a corresponding ListDefinition, holding the name of the list to query and its strongly typed field names. It’s the responsibility of a concrete repository to set the Definition property prior to doing any querying. After running a query, the Result property holds the weakly typed result, which a concrete repository can then transform into data transfer objects to be passed to the business layer.
As an example, add to the concrete EmployeeRepository any CRUD method you see necessary to fulfill the business requirements:
public class EmployeesRepository : ListRepository {
public EmployeesRepository() {
Definition = new EmployeesDefinition();
}
public void AddEmployee(SPWeb site, Employee e) {
var list = site.Lists[Definition.ListName];
var item = list.Items.Add();
item[EmployeesDefinition.EmployeeId] = e.Id;
item[EmployeesDefinition.Name] = e.Name;
item[EmployeesDefinition.HireDate] = e.HireDate;
item[EmployeesDefinition.Remarks] = e.Remarks;
item.Update();
}
public Employee GetEmployeeById(SPWeb site, int id) {
var caml =
string.Format(@"
<Where>
<Eq>
<FieldRef Name=""{0}"" />
<Value Type=""Integer"">{1}</Value>
</Eq>
</Where>",
EmployeesDefinition.EmployeeId, id);
Query(site, caml);
IList<Employee> employees = Map(Result);
if (employees.Count == 0)
throw new ArgumentException(string.Format("No employee with id = {0} exists", id));
return employees[0];
}
public ReadOnlyCollection<Employee> GetEmployeesHiredBetween(SPWeb site, DateTime from, DateTime to) {
var caml =
string.Format(@"
<Where>
<And>
<Geq>
<FieldRef Name=""{0}"" />
<Value IncludeTimeValue=""TRUE"" Type=""DateTime"">{1}</Value>
</Geq>
<Leq>
<FieldRef Name=""{0}"" />
<Value IncludeTimeValue=""TRUE"" Type=""DateTime"">{2}</Value>
</Leq>
</And>
</Where>",
EmployeesDefinition.HireDate,
SPUtility.CreateISO8601DateTimeFromSystemDateTime(from),
SPUtility.CreateISO8601DateTimeFromSystemDateTime(to));
Query(site, caml);
return new ReadOnlyCollection<Employee>(Map(Result));
}
protected IList<Employee> Map(SPListItemCollection items) {
var employees = new List<Employee>();
foreach (SPItem item in items) {
var e = new Employee {
Id = (int)item[EmployeesDefinition.EmployeeId],
Name = (string)item[EmployeesDefinition.Name],
HireDate = (DateTime)item[EmployeesDefinition.HireDate],
Remarks = (string)item[EmployeesDefinition.Remarks]
};
employees.Add(e);
}
return employees;
}
}
Calling the GetEmployeeById or GetEmployeesHiredBetween methods, the caller is required to pass in an SPWeb instance pointing to the site holding the list to query. Outside the SharePoint context, you have to manually create this instance, like with the integration tests above. But within the SharePoint context, callers are likely to just pass in SPContext.Current.Web.
The above repository implementation deliberately ignores any issue of caching. If you find the need for it, however, you can replace SPList.GetItem with PortalSiteMapProvider.GetCachedListItemsByQuery. The advantage of using the PortalSiteMapProvider over Asp.Net caching of the result is that the provider takes care of invalidating cache entries when items are modified. The disadvantage is that the provider is part of the SharePoint publishing API, which isn’t part of WSS 3.0. In addition, it’s only available from code running within SharePoint, and likely requires cache settings to be tweaked.
Another, non-trivial, improvement would include the use of the Unit of Work pattern. A commonly used pattern in ORMs because it offers a way to “keep track of everything you do during a business transaction that can affect the database. When you’re done, it figures out everything that needs to be done to alter the database as a result of your work". Like with the DataContext class in LINQ to SQL or the DataSet class in ADO.NET, it could add transaction support to SharePoint lists.